Risques d'erreurs
Le modèle H0
Lors d'un test d'hypothèses, l'expérimentateur doit choisir entre 2 hypothèses H0 et H1. La statistique lui fournit un outil de décision basé sur les probabilités.
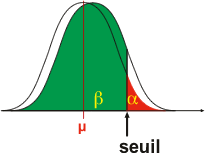
Si le modèle H0 est correct (modèle H0), 2 zones de probabilité sont définies
- alpha (ou erreur de type I): la probabilité de considérer la moyenne observée comme non conforme ou zone d'événements peu probables sous H0
- 1-alpha (ou confiance): la probabilité de considérer la moyenne observée comme conforme ou zone d'événements probables sous H0
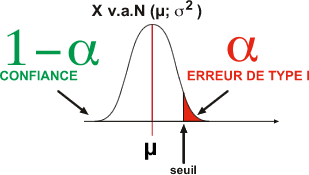
Si la moyenne observée est comprise dans la zone alpha, l'expérimentateur peut tirer une conclusion:
1. Voir un effet qui n'existe pas:
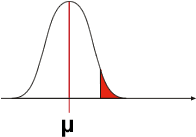
TOUS LES INDIVIDUS SOUS CETTE COURBE SONT CONFORMES
Si la moyenne observée de l'échantillon est comprise dans la zone alpha, cela peut signifier que l'échantillon est constitué fortuitement d'individus normaux dont la taille est exceptionnelle. La moyenne ainsi obtenue est peu probable mais toujours possible sous la courbe. Dans ce cas, l'expérimentateur va conclure erronément que l'échantillon n'appartient pas à la population centrée sur µ.
2. Voir un effet qui existe:
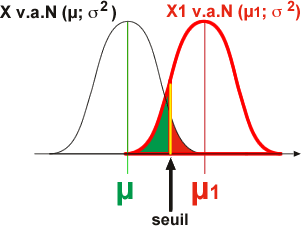
Si la moyenne observée de l'échantillon est comprise dans la zone alpha, cela peut signifier aussi que l'échantillon est constitué d'individus appartenant à une population de moyenne (µ1) distincte de µ (en rouge: cas où il existe une population centrée sur une moyenne µ1 plus grande que µ). L'expérimentateur en conclut que si il observe une telle moyenne c'est qu'elle provient d'une autre distribution (par exemple centrée sur µ1) où cette valeur est beaucoup plus probable.
Le modèle H1
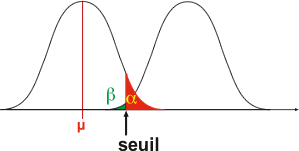
Le modèle H1 est représenté ici à droite du modèle Ho.
Dans le cas présent: H1 (µ1 supérieur à µ), représente un accroissement hypothétique du paramètre étudié, déplaçant ainsi la courbe à droite. Attention, il y a une différence fondamentale entre le modèle H0, qui est centré sur une moyenne µ connue et le modèle H1, centré sur une moyenne µ1 inconnue.
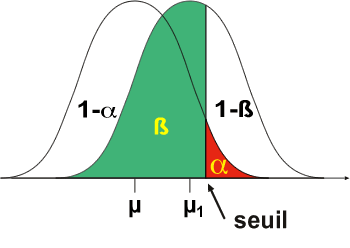
Ce modèle H1 est donc représenté à un endroit tout à fait arbitraire. Le seuil de signification définit sous la courbe deux zones distinctes:
En fonction de la position de la distribution H1 (µ1 proche de µ ou éloigné de µ), la probabilité de l'erreur de type II (β) peut être grande (proche de 100%) ou petite (proche de 0%). Comme la distribution H1 n'est jamais connue, la probabilité de l'erreur de type II n'est jamais connue, contrairement à la probabilité de l'erreur de type I (au maximum, égale à alpha). C'est la raison pour laquelle on dit qu'un test est non significatif quand on accepte l'H0 car on a aucune idée du risque d'erreur associé à cette décision. Par contre, on dira que le test est significatif quand on rejette H0 car on connait la probabilité de se tromper (au maximum, égale à alpha et bien souvent inférieure à alpha si la valeur observée est loin de la valeur seuil). L'expérimentateur cherchera donc à maximiser la puissance d'un test, c'est-à-dire à rejeter H0 à bon escient et à favoriser les conditions expérimentales qui augmentent cette puissance.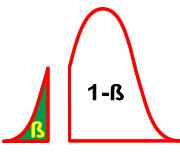
Objectif de l'expérimentateur
L'objectif de l'expérimentateur sera de mettre toutes les chances de son côté afin de voir le plus souvent possible un effet si cet effet existe réellement. Il va devoir jouer sur certains facteurs pour diminuer le recouvrement des deux courbes.
Non optimisé
- alpha: 5%
- confiance: 95%
- béta: 85%
- puissance: 15%
En d'autres termes, l'expérimentateur devra augmenter la puissance (1-β) le plus possible (bien souvent entre 80% et 99%) et donc diminuer la probabilité de ne pas mettre en évidence un effet qui existe réellement (l'erreur de type II β) à un minimum (bien souvent entre 20% et 1%) sans modifier la confiance du test du test.
Optimisé
- alpha: 5%
- confiance: 95%
- béta: 1%
- puissance: 99%
Animation
Optimisation d'une expérience
Supposons qu'un laboratoire pharmaceutique demande à l'un de ses chercheurs de montrer qu'une molécule X provoque une augmentation de la pression sanguine chez le rat.
L'employé doit mettre toutes les chances de son côté pour démontrer cet accroissement de la pression sanguine, pour cela, il peut contrôler les paramètres suivants s'ils existent :
| PARAMETRE |
COMMENT LE MODIFIER ? |
EFFET | MODIFIABLE? | |
| 1 | µ1 | Augmenter la dose du médicament | Augmentation de la distance entre les modèles | |
| 2 | Variance de la population | Cibler au mieux la population (rats mâles de 3 mois non stressés) | Resserrement des courbes autour de leur moyenne | |
| 3 | Taille d'échantillon | Augmenter la taille de l'échantillon | Resserrement des courbes autour de leur moyenne | |
| 4 | alpha | Augmenter alpha | Augmentation de RH0 même si pas d'effet à observer |
Optimisation d'une expérience: modifier µ1
Comment optimiser une expérience pour voir un effet le plus souvent possible?
1. Modifier µ1:
Il est parfois possible de modifier la moyenne µ1 de la distribution H1. Dans le cas d'un médicament, en augmentant la dose du médicament X (pour autant que cela soit faisable et réaliste), l'expérimentateur peut amplifier l'effet du médicament si le médicament a réellement un effet: il y aura un déplacement de la distribution H1 vers la droite.
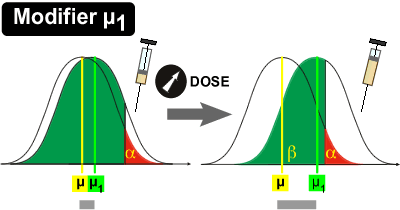
Il en résulte une diminution de la superposition des deux courbes et donc une augmentation de la puissance. Dans le schéma ci-dessus, la puissance reste faible (< 50%) et l'erreur bêta encore assez élevée (> 50%).
Optimisation d'une expérience: diminuer la variabilité (variance) des données
Comment optimiser une expérience pour voir un effet le plus souvent possible?
2. Diminuer la variabilité (variance) des données
Dans l'expérience portant sur l'effet d'une substance X sur la pression sanguine des rats, il est possible de diminuer la variance des données en sélectionnant par exemple, un lot de rats homogènes.
Le sexe, l'âge, le poids, le stress, la provenance des animaux jouent sur la pression sanguine et entraînent une grande variabilité des données. En sélectionnant un lot de rats homogènes (par exemple, rats mâles de 3 mois non stressés,...), on va diminuer la variabilité des données et il sera plus facile de voir si la substance a réellement un effet sur la pression sanguine. L'implication graphique de cette diminution de la variance se traduit par un resserrement de la courbe de Gauss autour de la moyenne.
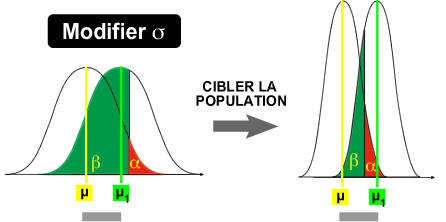
Il en résulte une diminution de la superposition des deux courbes et donc une augmentation de la puissance.
exemple: variance pour tous les rats = 225 [mm de Hg]2; variance pour des rats mâles de 3 mois non stressés = 25 [mm de Hg]2
Optimisation d'une expérience: augmenter la taille de l'échantillon
Comment optimiser une expérience pour voir un effet le plus souvent possible?
3. Augmenter la taille de l'échantillon
L'augmentation de la taille de l'échantillon a un effet similaire à celui observé lorsque l'expérimentateur réduit la variance des données. C'est le facteur que l'expérimentateur peut le plus facilement modifier, du moins en théorie.
Le théorème central limite nous apprend que la distribution d'échantillonnage des moyennes obéit à une distribution normale centrée sur µ et dont la variance est TeX Embedding failed!.
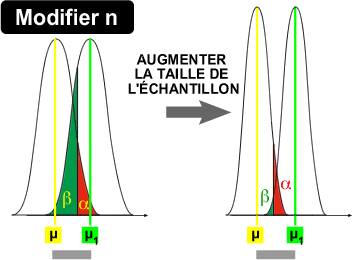
Il existe de nombreux programmes et algorithmes pour calculer la taille optimale de l'échantillon selon le plan expérimental. Pour ne pas devoir augmenter de manière exagérée la taille de l'échantillon à traiter, il est recommandé d'optimiser préalablement la distance entre µ et µ1 (si cela est possible) et de réduire au maximum la variabilité des données (homogénéité des facteurs expérimentaux) avant d'augmenter la taille de l'échantillon.
Supposons le test d'hypothèses suivant:
- H0: µ = µ1 = 120
- H1: µ1 > 120
- Confiance 95%
| CAS | Paramètres |
taille minimale de n pour une puissance de 99% et une confiance de 95% |
| 1 |
µ1=122 TeX Embedding failed! =225 |
887 rats |
| 2 |
µ1=124 TeX Embedding failed! =225 |
222 rats |
| 3 |
µ1=122 TeX Embedding failed! =25 |
99 rats |
| 4 |
µ1=124 TeX Embedding failed! =25 |
25 rats |
NB: L'expérimentateur ne peut déterminer la taille optimale de son échantillon pour avoir une puissance donnée qu'à condition de fixer la différence minimale (µ-µ1) qu'il désire mettre en évidence. La moyenne réelle µ1 reste inconnue, mais la différence µ-µ1 peut être inintéressante en dessous d'un certain seuil (par exemple, pas d'effet biologique si la différence est trop petite).
TeX Embedding failed!
Optimisation d'une expérience: augmenter alpha
Comment optimiser une expérience pour voir un effet le plus souvent possible?
4. Augmenter alpha 
Pour diminuer le recouvrement entre les distributions H0 et H1, l'expérimentateur pourrait être tenté d'augmenter la surface alpha afin d'accroître la puissance (1-β). Cette pratique n'est cependant pas recommandée. En effet, l'expérimentateur se doit de diminuer parallèlement les 2 types d'erreur, alpha et beta car il ne sait jamais au préalable quelle est la décision correcte (AH0 ou RH0).
L'expérimentateur délimite arbitrairement un intervalle de confiance (1-α) et une erreur de type I (α) mais par définition alpha doit être petit.
Soit il n'y a pas d'effet :
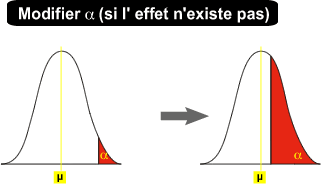
En augmentant alpha, l'expérimentateur rejettera plus souvent l'hypothèse nulle à tort.
Soit il y a un effet :
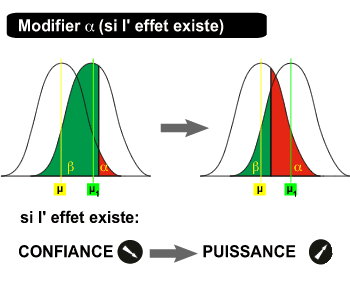
Si on réalise un test avec un grand alpha :
- En cas de RH0, la confiance est faible, le risque d'erreur de type I est grand (= alpha).
- En cas d'AH0, le risque d'erreur II est toujours inconnu.
En conclusion:
Si la valeur observée se retrouve dans la zone de rejet de l'hypothèse nulle, cela veut dire que:
- l'expérimentateur a obtenu une valeur observée qui est très éloignée de la moyenne de la population de référence. La probabilité de l'obtenir par hasard dans cette population de référence est très faible mais pas impossible (probabilité < alpha)
- La valeur observée est trop éloignée de la moyenne de la population de référence et l'expérimentateur en déduit qu'elle n'a pas été obtenue par hasard et, que par conséquent, le modèle H1 est très vraisemblable.
Remarques:
- Si un expérimentateur réduit la surface alpha pour diminuer la probabilité d'erreur de type I, cela entraîne une diminution de la puissance.
-
Si un expérimentateur fixe un alpha nul, il considérera toujours une valeur observée même anormale comme conforme.
Par exemple, si le alpha est très petit, le seuil de signification à atteindre pour considérer le poids d'un individu comme trop élevé est pratiquement impossible à atteindre. Le poids d'un sumo risque d'être assimilé à un poids tout à fait habituel chez un homme adulte alors qu'il devrait être considéré comme un obèse.
-
L'erreur de type I (alpha) résulte donc d'un compromis
-
alpha ne doit pas être trop grand. Si on rejette H0, il faut avoir une grande confiance en sa décision ou une probabilité d'erreur de type I faible (= alpha).
-
alpha ne doit pas être trop petit car s'il y a un effet à voir, le seuil de signification risque d'être impossible à atteindre vu son éloignement par rapport à la moyenne de la population de référence.
-
Exercices
1. Comparaison de dépenses en soins de santé entre deux pays
Des études de consommation ont été réalisées en Irlande et en Angleterre. Les dépenses en services médicaux et dépenses de santé représentaient, en 1985, respectivement 1,5% et 1% de la consommation totale des ménages. Sachant qu'en Europe, la variation des dépenses en services médicaux et dépenses de santé est de 1,9 (%²), combien de ménages doit-on étudier (alpha = 5%) dans ces deux pays pour montrer, dans 99% des cas, que la consommation totale en Irlande est supérieure à celle obtenue en Angleterre?
2. Etude d'un médicament hypertenseur
Soit une expérience portant sur l'étude d'un médicament hypertenseur expérimental. L'expérience est menée sur des rats de laboratoire dont on connait la pression sanguine habituelle: (120±15) mm de mercure.
L'effet attendu doit être plus grand que 124 mm de mercure (effet obtenu avec un médicament commercialisé depuis des années et bien caractérisé).
- De combien d'individus a-t-on besoin pour voir un effet dans 99% des cas sachant que l'intervalle de confiance est de 95%?
- Qu'en est-il avec une population de rats homogènes (même âge et même sexe) pour laquelle la variance est de 25mm²?