Distribution Normale
Généralités
La variable aléatoire normale est une variable continue dont la distribution est symétrique et suit une courbe de Gauss-Laplace. Beaucoup de variables biologiques suivent une loi normale.
Exemple: si l'on s'intéresse à la taille de chauves-souris, les individus peut être rangés dans des classes de tailles d'intervalles constants comme décrit précédemment dans les statistiques descriptives à une dimension. Si la population est composée d'un grand nombre d'individus, on peut les classer dans une infinité de classes d'intervalles Li tendant vers 0. L'histogramme est alors remplacé par une courbe de Gauss-Laplace:

Pour des échantillons de taille finie, l'ordonnée de l'histogramme se représente par des densités de fréquences relatives alors que pour la population on parle de densités de probabilités (n tend vers l'infini et delta x tend vers 0)
Propriétés
Equation et symbolique
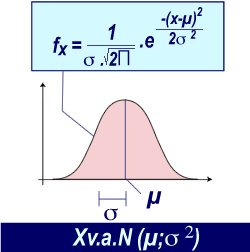
La fonction de densité de probabilités (fx) se caractérise par une équation faisant intervenir la moyenne µ et la variance σ2. Par convention, nous adopterons la convention d'écriture: X v.a.N(µ;σ2) . Dans la littérature, on peut aussi trouver: µ±σ (moyenne ± écart-type).
Symétrie autour de la moyenne
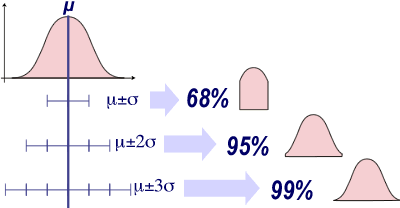
La courbe de Gauss-Laplace est symétrique:
- Lorsqu'on sélectionne l'intervalle compris entre +1 et -1 écart-type autour de la moyenne µ (de μ-σ jusque μ+σ), on isole 68% des individus d'une population normale.
- Lorsqu'on sélectionne l'intervalle compris entre +2 et -2 écarts-types autour de la moyenne µ (de μ-2σ jusque μ+2σ), on isole 95% des individus d'une population normale.
- Lorsqu'on sélectionne l'intervalle compris entre +3 et -3 écarts-types autour de la moyenne µ (de μ-3σ jusque μ+3σ), on isole 99% des individus d'une population normale.
Modification de la variance
Lorsque la variance d'une population diminue, cela se traduit par une dispersion moins importante de la courbe autour de la moyenne. Parallèlement, le sommet de la courbe tend à s'élever afin de préserver une surface totale sous la courbe égale à 1 (ou 100%).
Exemple:
Dans une population de chauves-souris de l'espèce A, l'envergure X est une v.a. N(375; 225)
Dans une population de chauves-souris de l'espèce A femelles, l'envergure X est une v.a. N(375; 121)
Dans une population de chauves-souris de l'espèce A femelles de 3 mois, l'envergure X est une v.a. N(375; 49)
etc.
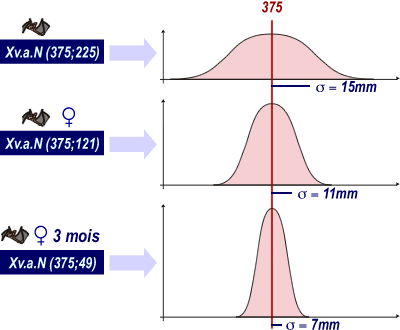
Influence de la variance sur le sommet de la courbe de Gauss:
Si la variance diminue, le sommet de la courbe tend à augmenter.
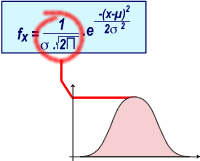
En effet, dans l'équation de la courbe, l'écart-type se trouve au dénominateur (voir terme entouré en rouge). Plus l'écart-type est petit, plus ce terme tend à devenir grand.
Réduction de variable
Chaque v.a. normale possède sa propre moyenne (µ) et variance (σ2). Déterminer des probabilités sous ce type de courbe de Gauss (à chaque cas particulier est associée une courbe de moyenne et de variance particulière) requiert un algorithme d'intégration numérique.
Heureusement, toutes les v.a. Normales peuvent se réduire à une seule et même distribution normale réduite Z. La distribution réduite de Z est centrée sur une moyenne 0 et possède une variance 1. La table de probabilité de Z a été calculée une fois pour toutes et dispense des probabilités du type:
P(Z ≤zi)
Comment réduire?
Toute v.a. normale peut être ramenée à une variable normale réduite Z v.a. N (0;1) par simple transformation algébrique (soustraction de la moyenne et division par l'écart-type). Cette opération est appelée réduction de la variable étudiée X en la variable réduite Z.
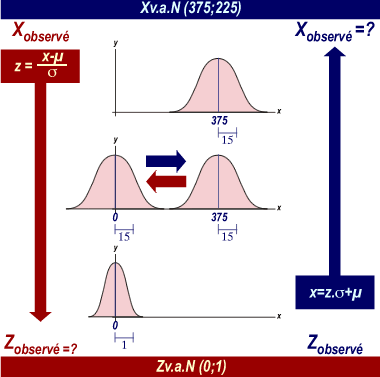
Convertir une valeur expérimentale (Xobservé) en une valeur réduite (Zobservé)
Xobservé = 390 et X v.a.N (375;225), alors TeX Embedding failed!
Convertir une valeur réduite (Zobservé) en une valeur expérimentale (Xobservé)
Zobservé = 2,5 et X v.a.N (375;225), alors TeX Embedding failed!
Théorème central limite
Le théorème central limite est un théorème mathématique qui définit les paramètres de la distribution d'échantillonnage, ou distribution des moyennes des échantillons en fonction des paramètres de la population de départ et la taille de d'échantillon.
Selon le théorème central limite, les moyennes des échantillons indépendants provenant d'une même population (µ;σ²) se distribuent selon une distribution normale de paramètres (TeX Embedding failed!).
Illustration avec une variable aléatoire normale
Soient x1, x2, x3 ... x∞ les tailles (cm) de truites arc-en-ciel. La taille de ces truites se distribue selon une distribution normale de paramètres :
X v.a. N(µ;σ²)
Si on prélève des échantillons indépendants (les poissons sont choisis au hasard) de n individus, toutes les moyennes de ces échantillons se distribuent selon une loi normale de même moyenne, mais de variance plus faible, avec TeX Embedding failed!.
La racine carrée de TeX Embedding failed! est appelée l'erreur standard de la moyenne (SEM ou standard error of the mean) ou encore écart-type de la moyenne.
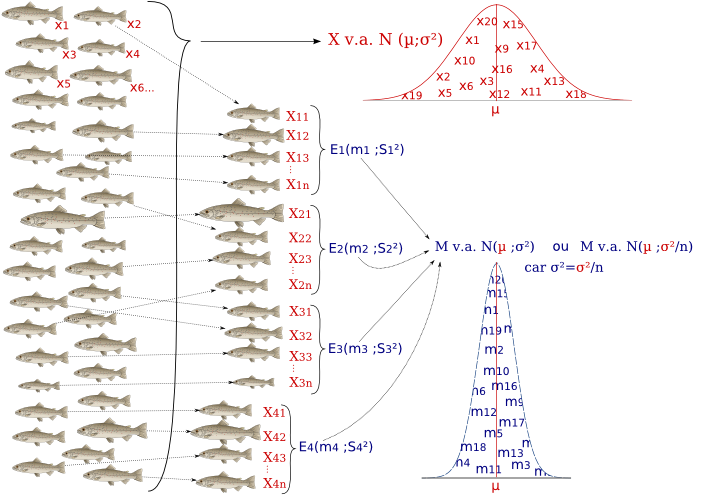
Exemples :
Si les truites proviennent d'une population normale de paramètres (15;4), les échantillons de 4 truites auront des moyennes qui se distribuent selon une loi normale de paramètres (15;1).
Si les truites proviennent d'une population normale de paramètres (20;12), les échantillons de 3 truites auront des moyennes qui se distribuent selon une loi normale de paramètres (20;4).
etc...
Illustration avec une variable Binomiale
Le théorème central limite s'applique aussi aux distributions discontinues telles que les distributions Binomiales ou de Poisson.
Prenons le cas du lancer d'un dé. Si le dé a 6 faces, et qu'il est équilibré, chaque face a 1/6ème de chance d'être affichée lors d'un lancer.
Si je lance le dé une seule fois, P(face=1)=P(face=3)=1/6
Si je lance le dé 10 fois P(moyenne=1)<P(moyenne=3)
Si je lance le dé 100 fois P(moyenne=1)<<<<<<P(moyenne=3)
etc...
Même si la variable est discontinue, la distribution des valeurs des moyennes des échantillons tend à suivre une loi normale de paramètres (µ;σ²/n) avec µ=moyenne de la population des valeurs de départ, et σ² la variance de cette population de départ, pour autant que la taille n de l'échantillon soit suffisamment grande.
Conséquence du théorème central limite
Lorsqu'on dispose des données de population (µ;σ²) et qu'on vous demande de calculer des probabilités associées à des valeurs moyennes réalisées sur n mesures, vous devez replacer ces valeurs moyennes dans leur distribution (TeX Embedding failed!) et non pas dans la distribution des valeurs des individus (µ;σ²).
Utilisation des tables de Z et de T de Student
Utilisation de la table de Z:
La table de Z (accessible depuis le lien "Tables" en haut de toutes les pages de ce site) vous donne les probabilités associées à des valeurs de z selon la relation p(Z<z).
Exemple : quelle est la probabilité d'avoir une valeur inférieure à 1,96 dans une distribution de Z v.a. N(0;1) ?
La table vous donne la réponse :
En tête de ligne on trouve la valeur entière et la première décimale de la valeur z.
En tête de colonne on trouve la seconde décimale de z.
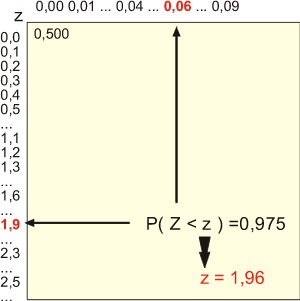
Donc P(Z<1,96)=0,975=97,5%
Inconvénient de la table de Z :
On peut lire la table à l'envers, donc par déduction, on peut y trouver les valeurs de Z qui correspondent à une certaine probabilité.
Cependant toutes les probabilités intéressantes ne sont pas forcément représentées.
Si, par exemple, on cherche le z en dessous duquel il y a 98,5% des individus, on cherche la valeur 0,985 dans les valeurs du tableau, et en regardant les en-têtes de ligne et de colonne je trouve que le z qui correspond est 2,17 (ligne 2,1 et colonne 0,07).
Mais si je cherche le z tel que P(Z<z)=0,8=80%, il n'y a pas 0,8 dans les valeurs. On passe de 0,79955 à 0,80234, donc le z tel que P(Z<z)=0,8 est compris entre 0,84 et 0,85.
Cette table peut donc s'employer dans le sens :
z connu --> trouver la probabilité P(Z ≤ z)
ou dans le sens :
probabilité P(Z ≤ z) connue--> trouver le z correspondant, mais elle n'est pas toujours pratique dans ce sens là.
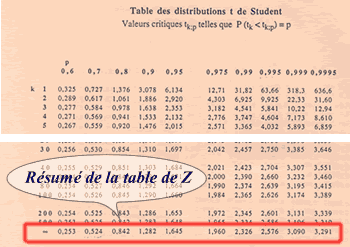
Utilisation de la table de Student :
La table de Student, telle que présentée dans ce site, part des probabilités et donne les valeurs des variables correspondantes de t selon le nombre de degrés de liberté de la variable t (en-tête de ligne).
Si la variance de la population est connue (σ2), on peut employer la table de t de Student pour retrouver la valeur de z en considérant qu' il s'agit d'une variable t où le nombre de dégrés de liberté est infini (dernière ligne).
L'avantage d'une telle table est de pouvoir donner rapidement des valeurs de Z pour des probabilités très couramment utilisées dans les tests d'hypothèses.
- En tête de colonne (p): donne la probabilité P(Z ≤ z)
- En tête de ligne (k): se positionner en l'"infini"
Dans notre exemple précédent :
P(Z<z)=0,8=80% donne ici directement une valeur exacte de 0,842.
En conclusion
Pour trouver une probabilité à partir d'une valeur de z : on utilise la table de Z.
Pour trouver une valeur de z à partir d'une probabilité fixée : on utilise la table de student, dernière ligne.
Exercices
Une vache produit quotidiennement 36 ± 5 litres de lait.
- Définissez la variable étudiée et ses paramètres.
- Quelle est la probabilité qu'une vache prise au hasard ait une production laitière inférieure à 30 l/jour ?
-
Quelle est la probabilité que la production laitière soit comprise entre :
- la moyenne plus ou moins 1 écart-type ?
- la moyenne plus ou moins 2 écarts-types ?
- La population comprend 5 % de vaches considérées comme étant des mauvaises productrices (faible production laitière), et 5 % de vaches considérées comme étant des excellentes productrices (production laitière élevée). Le reste de la population est considéré comme peuplé de vaches à production correcte. A partir de quelle production journalière peut-on considérer qu'une vache est mauvaise productrice ou excellente productrice ?
- Quelle est la probabilité qu'une productrice correcte produise moins de 36 l/jour ?
- Quelle est la probabilité qu'une productrice correcte ait une production inférieure à 30 l/jour ?
- Quelle est la probabilité qu'une vache ayant une production inférieure à 30 l/jour soit une productrice correcte ?
- Quelle est la probabilité qu'une vache prise au hasard soit une productrice laitière correcte et ai une production supérieure à 36 l/jour ?
Pour répondre vous devez consulter les tables.